Database & SQL
- Getting started
- Task – Insert
- Task – Select
- Task – Update
- Task – Remove a value
- Task – Combined Search condition
- Task – Search Using a Set
- Task – Search Using a Sub-select Set
- Task – Select Everything
- Summary
In previous chapters, you have learned how to create a static HTML page, then how to add dynamic content generated in a PHP script to that page. Then you have learned how to organize the PHP and HTML code using templates, so that it doesn’t become a complete mess.
So far it’s probably still a bit boring, because the data that the application displays is still somewhat hardcoded in the PHP script. We would like to make the application interactive, so that a user can permanently store and retrieve some arbitrary data. The answer to this is that we need a database server.
In this walkthrough I will be using a relational database, which means that the data is organized into tables. Specifically, I will be using PostgreSQL database, which is again a rather arbitrary choice, because for what we need, any relation database could be used.
Getting started
Before you get started, you need a database server and credentials to it. You also need an access to some kind of an administration interface, preferably a graphical one, so that you don’t get completely lost at the beginning.
To get you started as quickly as possible, I prepared a sample database for you. It contains the structure of the project and also some sample data, which is useful for testing your application. First you need to import the database, then you can start playing with it using the SQL language.
Import Database
I prepared files that you can import into the database, there are two files, the first one contains the definition of what tables do exist in the database and the second one contains sample data. Download both files (use ‘Save Link As’) and import both files using the procedure outlined below.
To import the file using the Adminer client. Click on Import, select the file you have downloaded, and click Execute. Repeat the process for both files:
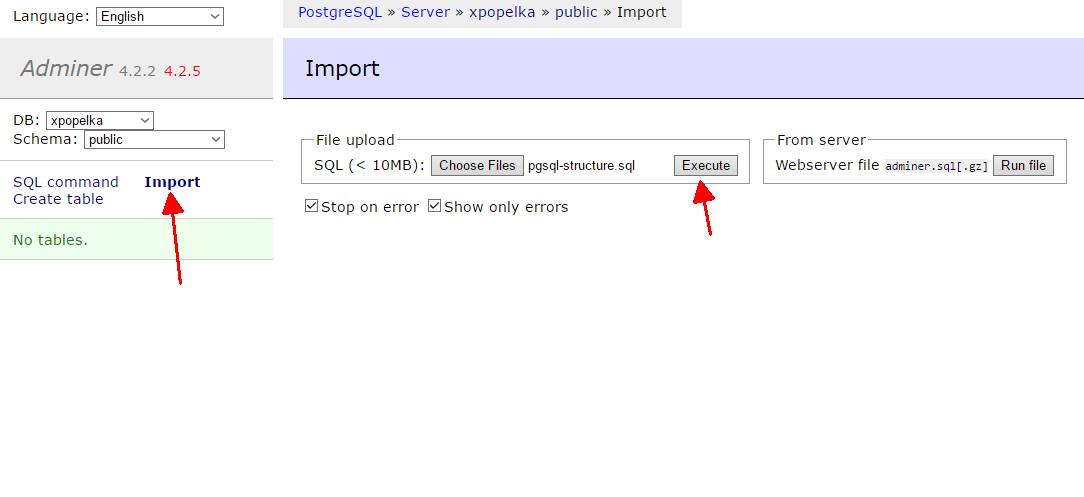
Once you have the structure of the database and the data imported, you should see, content in the Adminer:
SQL Language
SQL is a language which is used for communicating with most of the widely used database servers. If you have been following this Walkthrough from the beginning, then this is the fourth language you have learned so far (after HTML, PHP, Latte Macro Language).
The SQL language has only four everyday-use commands (there are dozens of others, which are rarely used and you can always look them up):
- INSERT for inserting data into the database
- UPDATE for modifying data already in the database
- DELETE for removing data from the database
- SELECT for obtaining data from the database
The first three commands are really simple, as you will see in the following exercise. The SELECT command is incredibly complicated and it usually takes years to learn all the intricacies connected with it (so I’ll start with some simple uses and leave the more difficult ones until later).
The SQL language is a programming language, but instead of writing lengthy pieces of a programming code as in PHP, we only write queries. An SQL query is a self-contained code piece – statement – instructing the database server to do something (e.g. delete some data). The query may contain other statements inside.
Database Schema
When working with a database, it is really important to know the structure of the database. The following graphic is the database schema and it shows each table, the columns in the table and their data types. It also shows relationships between the tables (which we won’t use much in this chapter). The design of a database structure is called Database Schema. Keep it handy.

As we are working with a relational database system, data is stored in tables. Each table has columns (with some name and datatype – as defined in the database schema) and rows which contain the actual data. Most operations in SQL work on full rows – sometimes called records.
In SQL the keywords are usually written ALL CAPS, this
is just a convention to improve readability. It has no effect on the query itself. SQL statements
are delimited by the semicolon ;. Because in most cases, only a single SQL statement is used, the
semicolon at the end of it may be safely omitted (it is a delimiter, not terminator).
Reading Database Structure
When you have the database schema imported into your own database, you should take time to
explore it in more detail. The database schema pictured above gives you only a general overview
of what structure is defined for the data. In fact the database schema defines all
integrity constraints. Examine
the structure of the person table in your database:
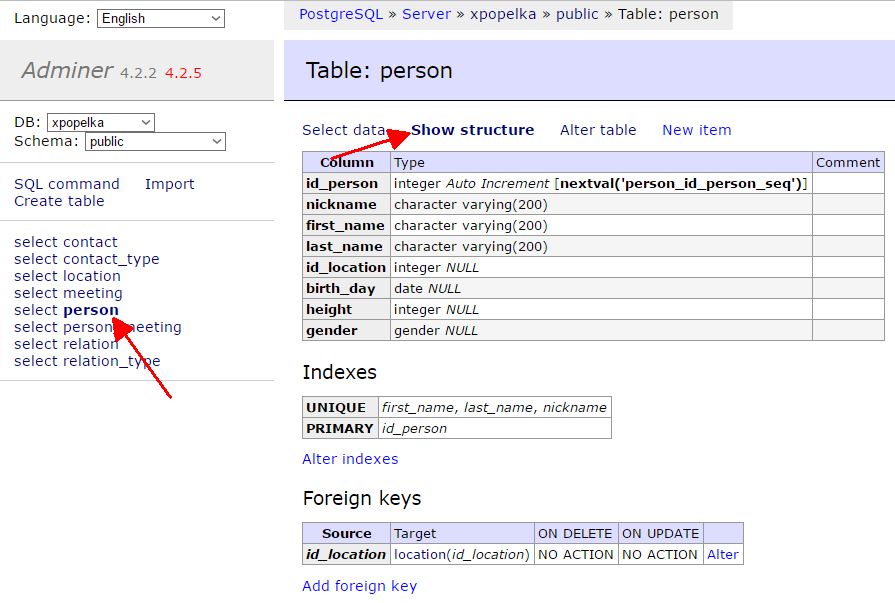
Here you can see for example that:
- the column
id_personhas the data typeinteger, - the column
id_personis an automatically generated key (Auto Increment), - the column
id_personhas the default valuenextval('person_id_person_seq')(next value of a sequence), - the column
birth_dayhas the data typedate, - the column
birth_dayallows insertingNULL, - the column
genderhas the typegender(a special type defined in your database), - there is a simple key defined on the
id_personcolumn (PRIMARY key), - there is a compound key defined on the combination of the columns
first_name, last_name, nickname(UNIQUE), - there is a foreign key on the
id_locationcolumn, so that it points to thelocationtableid_locationcolumn (source: id_location; target: location(id_location)).
And much more. Take time to examine the other tables as well so that you are acquainted with the database structure.
INSERT
The general syntax of the INSERT command is:
INSERT INTO table_name (list_of_columns) VALUES (list_of_values)The INSERT statement inserts rows into a table.
When you look at the schema, you should see that the location table has the columns:
id_location, city, street_name, street_number, zip, country, location, latitude, longitude.
The column types of latitude and longitude is numeric which is a decimal number (GPS coordinates) and
the type of id_location and street_number is integer. All other columns have the type character varying which
is another name for a string. All of the columns except id_location allow
NULLs and
the column id_location has a default value, which means that the all of the columns are optional.
Columns with automatically generated IDs – such as id_location in this table – are
almost never inserted.
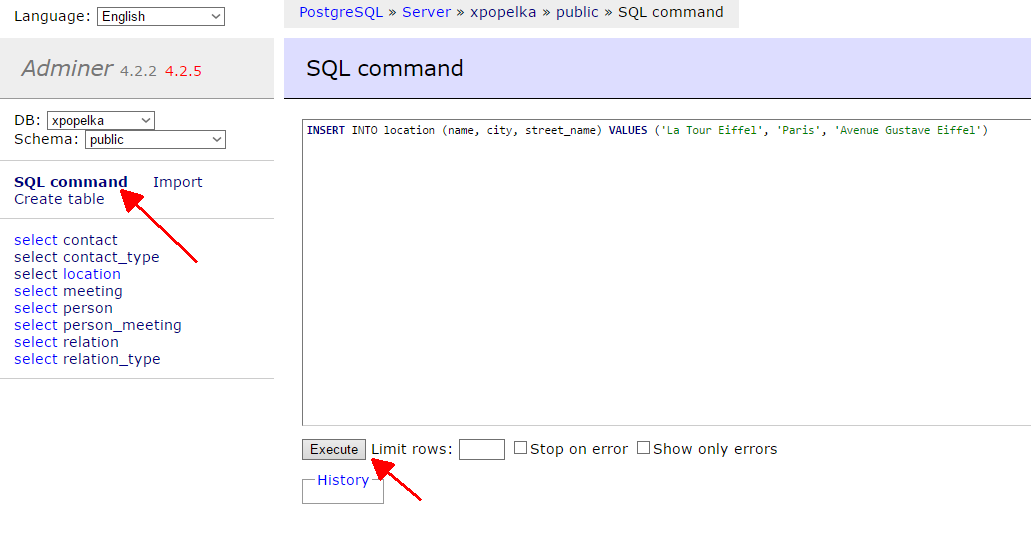
Let’s insert some data into the location table:
INSERT INTO location (name, city, street_name) VALUES ('La Tour Eiffel', 'Paris', 'Avenue Gustave Eiffel')The order of the inserted values must match the order of the column names, this (obviously?) means that there must be the same number of items in the column list and value list. Try to run the query yourself in the Adminer:
Important: Unlike in HTML and PHP, in SQL, strings must always be enclosed in single
quotes '. Double quotes are not allowed for string values. Actually double quotes
are used to quote the column and table names.
You should see the result
Query executed OK, 1 row affected.
Click on select next to the location table to verify that the row really got inserted into the table.
That’s – once you know the structure of the destination table, writing an SQL INSERT statement is easy.
Notice that there are two keywords used at the beginning of the query INSERT INTO. If you have some
programming background, this may look unusual to you. It is supposed to improve the readability of the
SQL query. In SQL it is quite common, so you better get used to it.
The list of the columns is not required, so the above query may also be shortened to:
INSERT INTO location VALUES (DEFAULT, 'Paris', 'Avenue Gustave Eiffel', NULL, NULL, NULL, 'La Tour Eiffel')I highly discourage you from using this form of INSERT query in your application. It breaks as soon as you make some modifications to the table. Also just from reading it, it is very hard to understand what gets inserted where. It is better to be explicit and verbose.
DEFAULT and NULL
They keyword DEFAULT means that a default value of the column should be used (in the above case,
it is a sequence value – nextval('location_id_location_seq'::regclass)). The keyword
NULL means that no value will be inserted into that column.
If you don’t list a column in the
INSERT query, then it is the same as if you listed it with the DEFAULT keyword.
Then it depends on the definition of the column:
- If the column has a default value, then that value is inserted.
- If the column has not a default value, then:
- If the column allows NULLs, no value is inserted (NULL).
- If the column requires a value (defined as
NOT NULL), an error is raised – a required value for the table column was not provided in the INSERT query
Working with Dates
Although dates are printed as strings, the database server stores them in a timestamp format. When inserting a date, you must make sure that the server understands it correctly by either:
- supplying the date in the format expected by the server (usually
YYYY-MM-DD), - or explicitly converting the date with a conversion function.
The first option depends on the configuration of the database server, but it is fairly common that this query works:
INSERT INTO person (first_name, last_name, nickname, birth_day)
VALUES ('John', 'Doe', 'Johnnie', '2010-12-24')Using a conversion function is safer, but slightly more complicated. There are a lot of differences between various database servers. However, the general principle is that you supply date in an arbitrary format and a description of that format:
INSERT INTO person (first_name, last_name, nickname, birth_day)
VALUES ('John', 'Doe', 'Johnnie', TO_TIMESTAMP('24.12.2010', 'DD.MM.YYYY'),)In the above query, I have used the TO_TIMESTAMP function of the PostgreSQL database server. The first argument to the function is the date (in any format). The second argument to that function is the format description with a formatting string. This way you tell the server that the date starts with two digits representing a date and followed by a dot.
The date conversion functions are specific to each database server. While they share the same principle, they may have different names and parameters. Always consult the manual of the database server you are using (look for the section ‘Date conversion functions’).
UPDATE
The general syntax of the UPDATE command is:
UPDATE table_name SET list_of_modifications WHERE search_conditionThe UPDATE command updates existing values in existing rows in the table. The list_of_modifications is a list of assignments to be made. The search_condition is an expression which is evaluated for each row and should yield a boolean value. If the search_condition is true, the corresponding row is updated, otherwise it is skipped.
Let’s update a row in the location table:
UPDATE location SET name = 'Arc de Triomphe', street_name = 'Place Charles de Gaulle'
WHERE name = 'La Tour Eiffel'Note that the same character = is used for both comparison (WHERE clause) and
assignment (SET clause). In SQL the actual function of the equal sign is determined by
the context. There is no == operator in SQL.
The search condition can be composed of multiple statements joined using the boolean operators AND, OR and NOT.
Notice that you can reference a column in both the search condition and in the assignment (name in the
above example). Also, the new value of the column may be an expression, so it’s valid to write e.g.:
... SET age = age + 1 ....
Search condition
Important: the WHERE condition is not required, if you forget it,
all rows in the table will be updated. Also, notice that NULLs need to be
treated specially.
Typically you use key columns in the search
condition to update a single record. Be careful
about this – if you are using a compound key,
then all columns of that key must be used
in the condition. Consider this query:
UPDATE person SET height = '135' WHERE first_name = 'John' AND last_name = 'Doe'There is a compound key on the columns first_name, last_name, nickname defined on
the persons table (UNIQUE (first_name, last_name, nickname)). This guarantees that
the combination of the first name, last name and nickname of a person is unique
(in your database that is). However the combination of first_name and last_name
is not guaranteed to be unique and therefore the query may update more than
one person and therefore it is wrong. There are two correct options:
UPDATE person SET height = '135'
WHERE first_name = 'John' AND last_name = 'Doe' AND nickname = 'Johnnie'UPDATE person SET height = '135' WHERE id_person='42'Either of the above two solutions is fine, but any other solutions are wrong. When you are modifying data in database, you must make sure that there is no possibility of changing unwanted rows.
DELETE
The general syntax of the DELETE command is:
DELETE FROM table_name WHERE search_conditionThe DELETE command removes entire rows from the table. Same rules apply for the search_condition as in
the UPDATE statement. Including that – if you forget the WHERE statement, then
all rows of the table will be deleted!.
Let’s delete the row, we have just inserted:
DELETE FROM person WHERE id_person > 50I have used the larger than > operator to delete any location inserted after the initial import.
You will usually use the equals = operator.
SELECT
The general syntax of a simple SELECT command is:
SELECT column_list FROM table_name WHERE search_condition ORDER BY list_of_orderingsThe SELECT command returns rows of an existing table (or tables) and returns
them in the form of a table. The column_list is either a list of column names or
asterisk * to list all columns of the table.
The same rules apply to the search_condition as in the previous commands, including that
if you omit the WHERE statement altogether, all rows of a table will be returned.
SELECT * FROM location WHERE id_location > 40There are some useful features
which you can use in the WHERE clause. You should
definitely be aware of the existence of LIKE and IN operators.
The LIKE operator is useful for selecting a string by a partial match. Use the percent sign % as
a placeholder for any number of characters:
SELECT * FROM location WHERE city LIKE 'B%'The above example selects all locations where city starts with letter B.
The IN operator is useful for matching against a set of values. The following will select
all locations the city of which is one of those mentioned in the set (defined in the parenthesis):
SELECT * FROM location WHERE city IN ('Praha', 'Paris', 'Bremen')The set can be either enumerated as in the above example or it can be defined by another
SELECT query. To exclude set values from the result
use the column NOT IN (...) variant
(also with NULL value use column IS NOT NULL).
ORDER BY
Ordering of the results is possible by multiple criteria:
SELECT * FROM location ORDER BY cityCompare the result of the above query with the result of the below query. Look at multiple rows with the same city - e.g. Brno.
SELECT * FROM location ORDER BY city, street_nameEach column ordering can be further modified by the direction keyword either ASC (ascending sorting – A-Z)
or DESC (descending sorting – Z-A). If no direction is specified, then ASC is assumed.
Note that the direction must be specified for each column individually, so the
query
SELECT * FROM location ORDER BY city, street_name DESCWill not fully reverse the table, but the following query will:
SELECT * FROM location ORDER BY city DESC, street_name DESCImportant: If you omit the ORDER BY statement, the rows in the result are
ordered randomly. You should therefore use defined ordering for every SELECT
whose result is displayed to the end-user.
Task – Insert
Insert a person named Karl Oshiro, with his nickname hiromi, gender = ‘male’ and height = 180.
INSERT INTO person (first_name, last_name, nickname, gender, height) VALUES
('Karl', 'Oshiro', 'hiromi', 'male', 180)Task – Select
Select id_person of this Karl Oshiro, you have just inserted, make sure to return only a single row.
SELECT id_person FROM person
WHERE first_name = 'Karl' AND last_name = 'Oshiro' AND nickname = 'hiromi'Task – Update
Change the name of the Karl Oshiro you just inserted to Carl Sohiro, make sure to update only a single row – find the right ID in your database.
UPDATE person SET first_name = 'Carl', last_name = 'Oshiro' WHERE
id_person = 49UPDATE person SET first_name = 'Carl', last_name = 'Oshiro' WHERE
WHERE first_name = 'Karl' AND last_name = 'Oshiro' AND nickname = 'hiromi'Task – Remove a value
Remove the value of height for Carl Sohiro.
Hint: you must set the value to `NULL`.UPDATE person SET height = NULL WHERE id_person = 49You cannot use a DELETE command, because that deletes entire rows. Also you
mustn’t set the value to 0, because there is a difference between 0 height and
an unknown height.
Task – Combined Search condition
Find all persons whose last names begin with C or K and their heights are more than 170 centimeters.
Hint: You'll need an `OR`, an `AND` and `LIKE`.Hint: If you have the sample data, then three rows should be returned. If you got
more, double check the results.SELECT * FROM person WHERE (last_name LIKE 'C%' OR last_name LIKE 'K%') AND height > 170Task – Search Using a Set
Select all persons with names ‘Gilda’, ‘Alisha’ and ‘Lisette’ and order them so that the tallest are shown first.
SELECT * FROM person WHERE first_name IN ('Gilda', 'Alisha', 'Lisette') ORDER BY height ASCTask – Search Using a Sub-select Set
Select all persons which have associated location in the country United Kingdom and order
them by the last_name column. Now you will need to write two SELECTs and connect them using the IN
operator.
Hint: Start by selecting id_location of the locations in the United Kingdom. You should
get 12 rows with the sample data.
Hint: Write a SELECT statement that uses the previous SELECT inside the parenthesis of the IN operator.
SELECT * FROM person WHERE id_location IN
(SELECT id_location FROM location WHERE country = 'United Kingdom')
ORDER BY last_nameTask – Select Everything
Just a verification – select all rows and all columns from the persons table.
SELECT * FROM personSummary
Now you should know how to work with a relational database. There is much more to come, but
so far, you should be able to SELECT, INSERT, UPDATE and DELETE data. This is
sufficient to create a reasonably working web application. Just note that some techniques have not been
revealed to you yet – be patient and read on! If you do not know how to do something
(find ID of an inserted row, limit the amount of returned results, calculate the number of entries…)
do not try to come up with your own solution, database systems are widely used for many years
and there are tools and procedures how to do these things correctly.
You should be familiar with the general syntax of SQL statements, the common key words, and
SQL specific operators (LIKE, IN). Do not be afraid to experiment with your database,
you can always delete it (and import it again) by using the SQL queries:
DROP TABLE relation CASCADE;
DROP TABLE relation_type CASCADE;
DROP TABLE contact CASCADE;
DROP TABLE contact_type CASCADE;
DROP TABLE person_meeting CASCADE;
DROP TABLE meeting CASCADE;
DROP TABLE person CASCADE;
DROP TABLE location CASCADE;
DROP TYPE gender;New Concepts and Terms
- (Relational) Database
- Database Schema
- Tables
- SELECT
- INSERT
- UPDATE
- DELETE
Control question
- What does DELETE or UPDATE query without WHERE clause do?
- Is it necessary to specify all attributes when inserting data?
- How would you delete person’s birth day?
- Do you need to use uppercase for SQL keywords?
- Is it common to change structure of a table (add/remove column) during application lifetime?